定宽数组
- 定宽数组(Fixed-Size Arrays)是SV中用于存储固定数量元素的静态数据结构
- 编译时确定大小,运行时不改变容量,在内存中连续存储,支持高效索引访问
特性与声明
- 基础格式:
<数据类型> <数组名>[<维度1>][<维度2>]...;
- 紧凑声明:SV允许只声明数组宽带,使用0作为索引下界
- 格式化描述符:可使用
%p打印数组、结构、类等
- SV仿真器存放数组元素时使用字边界

1
2
3
4
| int array1[0:7];
logic [31:0] arry2[0:3][0:2];
int array1[8];
logic [31:0] arry2[4][3];
|
- 常量数组初始化
- 使用一个单引号加大括号来初始化数组,为部分或所有元素赋值
1
2
3
4
5
6
7
8
9
10
11
| initial begin
int a[5];
static int b[4] = '{0, 1, 2, 3};
int c[2][3];
a = '{4,3,2,1,0};
a = '{7,6,5};
b = '{4{8}};
b = '{default:42};
c = '{'{0,1,2},'{3,4,5}};
c[2][3] = 1;
end
|
foreach循环
1
2
3
4
5
6
7
8
9
10
| initial begin
bit [31:0] src[5], dst[5];
int rev[6:2];
for (int i = 0; i<$size(src); i++)
src[i] = i;
foreach (dst[j])
dst[j] = src[j] * 2;
foreach (rev[k])
rev[k] = k;
end
|
- 多维数组使用foreach,用逗号将下标隔开后放在同一个方括号中
- 若不需要遍历所有维度,可以在方括号中忽略掉它们
1
2
3
4
5
6
7
8
9
10
11
| int md[2][3] = '{'{0,1,2},'{3,4,5}};
initial begin
foreach (md[i,j])
$display("md[%d][%d] = %d", i, j, md[i][j]);
foreach (md[i]) begin
$write("%2d:", i);
foreach (md[,j])
$write("md[%d][%d] = %d", i, j, md[i][j]);
$display;
end
end
|
比较和复制
- 可以不使用循环而对数组进行聚合比较和复制,聚合操作适用于整个数组而不是单个元素
- 对于数组的加、减法等算术运算不能使用聚合操作,应该使用foreach循环
- 对于异或等逻辑运算,应该使用循环或合并数组
1
2
3
4
5
6
7
8
9
10
| initial begin
bit [31:0] src[5] = '{0,1,2,3,4}, dst[5] = '{5,4,3,2,1};
$display("src %s dst", (src == dst) ? "==" : "!=");
dst = src
$display("src[1:4] %s dst[1:4]",
(src[1:4] == dst[1:4]) ? "==" : "!=");
$displayb("dst[0][2:1]");
end
|
合并数组
特性与声明
- 合并数组是一种特殊的多维数组,其所有维度在内存中连续存储
- 区别于普通向量,合并数组适合处理具有自然分层的结构(如网络包、图像数据)
- 区别于普通数组使用字边界的存放方式,使得合并数组支持直接的位级操作(如异或运算)
- 声明合并数组时,数组大小和合并位宽必须在变量名前指定
- 数组大小格式必须是
[msb:lsb],而不是[size]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| logic [31:0] A;
logic [3:0] B[8];
logic [3:0] [7:0] C;
int [1:0] D;
|
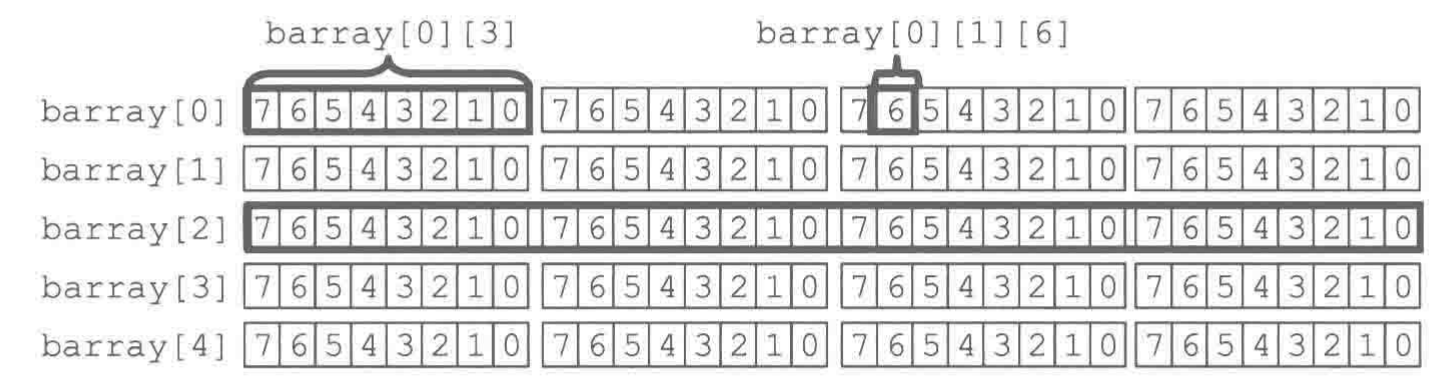
混合使用
- 合并数组(Packed Array)和非合并数组(Unpacked Array)可以混合使用
- 合并数组作为非合并数组的元素类型
- 支持更复杂的硬件建模需求,如数据包、寄存器组
- 优化内存布局:合并部分连续、非合并灵活分散
1
2
3
4
5
6
|
bit [3:0] [7:0] barray [5];
bit [31:0] oneword = 32'h012345678;
barray[0] = oneword;
|
动态数组
特性与声明
- 动态数组在声明时使用空的下标
[],表示数组尺寸在编译时未指定
- 仿真运行时通过
new[]操作符显式地预分配内存大小
1
2
3
4
5
6
7
8
| int dyn[],d2[];
initial begin
dyn = new[5];
foreach (dyn[j]) dyn[j] = j;
d2 = dyn;
dyn = new[20](dyn);
dyn = new[100];
end
|
- 基本数据类型(如
int)相同,定宽数组和动态数据之间可以相互赋值
- 当把一个定宽数组复制给一个动态数组时,会自动分配空间
- 适用于想声明一个常数数组但又不想统计元素的个数
1
| bit [1:0] mask[] = `{2'b00, 2'b01, 2'b10, 2'b11};
|
1
2
3
4
5
6
| int d[][];
initial begin
d = new[4];
foreach (d[i]) d[i] = new[i+123];
foreach (d[i,j]) d[i][j] = i + j;
end
|
常用内建方法
- 长度操作:
array.size()获取数组当前元素个数,等同于$size(array)
- 删除内存:
array.delete()释放数组内存
- 插入元素:
array.insert(index, value)在指定索引位置插入元素,数组大小自动增加
- 删除元素:
array.delete(index)删除指定索引处的元素,数组大小减1
动态数据使用上述内建函数消耗性能,更多内建方法见最后一章
队列
特性与声明
- 队列 (queues) 特性
- 动态:队列长度在仿真期间自动伸缩,无需预分配大小
- 同质:队列中所有元素的类型必须相同
- 有序:队列中的元素是有序的,能够通过索引访问
- 高效操作:SV提供内置的方法高效地在队列的任意位置删减元素
- 队列声明
- 声明队列的语法与数组类似,但需使用
$
- 队列的常量初始化不再需要使用
'
1
2
3
| int my_int_q[$];
my_class_type my_object_q[$];
my_int_q[$] = {1,2,3,4};
|
1
2
3
4
5
| bit [31:0] pk_addr, pk_csm, pk_data[8];
bit [31:0] upk_addr, upk_csm, upk_data[8];
byte bytes[$];
bytes = { >> {pk_addr, pk_csm, pk_data}};
{ >> {upk_addr, upk_csm, upk_data}} = bytes;
|
常用内建方法
- 长度操作:
q.size()返回队列中元素的当前数量,等同于$size(q)
- 删除内存:
array.delete()释放数组内存
- 删除元素:
q.delete(index)删除指定索引处的元素
- 插入元素:
q.insert(index, item)在指定索引处插入一个元素
- 头部插入:
q.push_front(item)在队列的头部插入一个元素
- 尾部插入:
q.push_back(item)在队列的尾部插入一个元素
- 头部发送:
q.pop_front()移除并返回队列头部的元素
- 尾部发送:
q.pop_back()移除并返回队列尾部的元素
- 移除重复:
q.unique()移除队列中的重复元素
关联数组
特性与声明
- 关联数组(Associative Arrays)允许使用任意类型(如整型、字符串等)作为索引(键Key),快速存取对应的值,原理示例
Key: “apple” -> 哈希表 -> 索引值 -> 定位存储位置(通)-> 返回值
- 动态:内存仅在写入元素时分配,无需预分配
- 无序:存储非连续索引的数据(如大范围地址的稀疏数据),避免内存浪费
- 灵活:索引可以为任意类型

- 声明格式:
data_type array_name [index_type];
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int fruit_prices[string] = '{"apple": 5, "banana": 3, "orange": 4};
fruit_prices["grape"] = 6;
foreach (fruit_prices[i]) begin
$display("fruit_prices[%s] = %0d", i, fruit_prices[i]);
end
string key;
if (my_array.first(key)) begin
do begin
$display("my_array[%s] = %0d", key, my_array[key]);
end while (my_array.next(key));
end
|
常用内建方法
- 删除内存:
array.delete()
- 删除键值对:
array.delete(key)
- 检查键存在:
array.exitsts(key)检查指定键是否存在,若存在返回布尔值1
- 数量查询:
array.nun()查询数组中键值对的总数量
- 获取首键:
array.first(ref)获取第一个键赋值给参数ref
- 获取未键:
array.last(ref)获取最后一个键赋值给参数ref
- 获取下一键:
array.next(ref)获取下一个键赋值给参数ref
- 获取上一键:
array.prev(ref)获取上一个键赋值给参数ref
1
2
3
4
5
6
7
8
9
10
11
12
13
| class memory_model;
byte memory[int];
function void write(int addr, byte data);
memory[addr] = data;
endfunction
function byte read(int addr);
if (memory.exists(addr)) return memory[addr];
else return 0;
endfunction
endclass
|
数组的方法
- 数组内建方法汇总,使用于任何非合并的数组类型,包括定宽数组、动态数组、队列和关联数组
缩减
- 数组的缩减方法是指将数组缩减成一个值,结果和元素的位宽一致
- 缩减方法可以用来计算数组中所有元素的和、积或逻辑运算
- 和积:
array.sum()、array.product()
- 与或:
array.and()、array.or()
- 异或:
array.xor()
- SV并没有内建从数组中随机选取一个元素的方法,但可以生成一个随机索引
1
2
3
4
5
6
7
8
9
| int my_array[4] = '{1, 2, 3, 4};
int random_index, selected_element;
random_index = $urandom_range(my_array.size() - 1, 0);
selected_element = my_array[random_index];
$display("随机选取的元素: %d", selected_element);
|
定位/条件
- 用于查找数组中所有满足指定条件的元素,并将结果以队列形式(无
')返回
- 数组定位方法:min、max、unique
array.min()和array.max()返回数组的最值队列array.unique()返回数组中唯一值的队列
- 数组定位方法:find
array.find() with (condition)强制使用with语句查找指定条件,并以队列形式返回
- 无匹配时返回空队列
{},需在代码中检查结果中是否有效
with支持复杂逻辑,如item > 2 && intem < 8
array.find_first() with (conditon)以队列形式返回首个满足条件的元素array.find_last() with (conditon)以队列形式返回最后一个满足条件的元素array.find_index() with (conditon)以队列形式返回首个满足条件的元素的索引
- 对于
find_index方法,返回的队列类型是双状态int而不是四状态integer
1
2
3
4
5
6
| int arr[] = '{3, 7, 2, 9, 5};
int found_queue[$] = arr.find() with (item > 5);
found_queue = arr.find_first() with (item % 2 == 0);
found_queue = arr.find_last() with (item < 6);
int index_queue[$] = arr.find_index() with (item == 9);
|
- 在条件语句
with中,item被称为重复参数,是一个缺省的名字,也可以指定其他名字,以下四个语句是等同的
1
2
3
4
| found_queue = arr.find() with (item == 3);
found_queue = arr.find with (item == 3);
found_queue = arr.find(item) with (item == 3);
found_queue = arr.find(x) with (x == 3);
|
- 当把数组缩减方法
sum()与条件语句with结合使用时,可以检测表达式为真的次数
1
2
3
4
| int count, total, d[] = `{9,1,8,3,4,4};
count = d.sum(x) with (x > 7);
total = d.sum(x) with ((x > 7) * x)
total = d.sum(x) with (x < 8 ? x : 0)
|
- 下面介绍了一种使用数组定位方法建立记分板的方法,使用
typedef创建包结构(对于包信息的存储,更好的方法是使用类)
- 例子中
check_addr()函数在计分板中寻找和参数匹配的地址
find_index()方法返回一个int队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| typedef struct packed {
bit [7:0] addr;
bit [7:0] pr;
bit [15:0] data;
} Packet;
Packet scb[$];
function void check_addr(bit [7:0] addr);
int intq[$];
intq = scb.find_index() with (item.addr == addr);
case(intq.size())
0: $display("Addr %h not found in scoreboard", addr);
1: scb.delete(intq[0]);
default: $display("ERROR: Multiple hits for addr %h", addr);
endcase
endfunction : check_addr
|
排序
- 只有定宽数组、动态数组、队列可以排序、反转、打乱次序,关联数组不能重新排序
- 排序方法改变了原始数组,而定位方法是新建一个队列来保存结果
array.sort()按照元素大小进行升序排序array.rsort()按照元素大小进行降序排序array.reverse()反转数组中元素的顺序array.shuffle()打乱数组中元素的顺序
1
2
3
4
5
| int d[] = '{9,1,8,3,4,4};
d.sort();
d.rsort();
d.reverse();
d.shuffle();
|
- 使用子域对一个结构数组进行排序时,
reverse和shuffle方法不能带with语句
1
2
3
4
5
6
| struct packed { bit [7:0] red, green, blue} color[];
color = '{'{red:7, grean:4, blue:9}, '{red:3, grean:2, blue:9}, '{red:5, grean:2, blue:1}};
color.sort with (item.red);
color.sort(x) with (x.green, x.blue)
|
选择数据结构
本章介绍一些如何正确选择存储类型(数据结构)的经验法则
- 网络数据包建模
- 特点:长度固定、顺序读取
- 针对长度固定或可变的数据可分别采用定宽数组或动态数组
- 保存期望值的记分板
- 特点:仿真前长度位置,按值存取,长度经常变化
- 一般情况下可使用队列,方便在仿真期间连续增加和删除元素
- 如果记分板由数百个元素,而且需要经常对元素进行增删操作,则使用关联数组在速度上可能更快
- 如果将事务建模成对象,那么记分板可以是句柄的队列
- 如果不用记分板进行搜索,那么只需要把预期的数值存入信箱(mailbox)
- 有序结构
- 如果数据按照可预见的顺序输出,可以使用队列
- 如果输出顺序不确定,则使用关联数组
- 对特大容量存储器建模
- 如果不需要用到所有存储空间,可以使用关联数组实现稀疏存储
- 确保使用的是双状态类型的32比特合并数据,以节约仿真器使用的内存
- 文件中的命令名或操作码
- 特点:把字符串转换成固定值
- 从文件中读出字符串,然后使用命令作为字符串索引在关联数组中查找命令名或操作码